In the previous blog we learned about collaborative filtering which uses user-item interactions only.
Idea for Collaborative Filtering – “Users who behaved similarly in the past will behave similarly in the future”. You can read entire blog here – https://vaibhavshrivastava.com/recommender-systems-collaborative-filtering/
I recommend opening this notebook side by side to refer to code in topics at the later stages of the blog – https://www.kaggle.com/code/innomight/recommendation-systems-content-based-simple
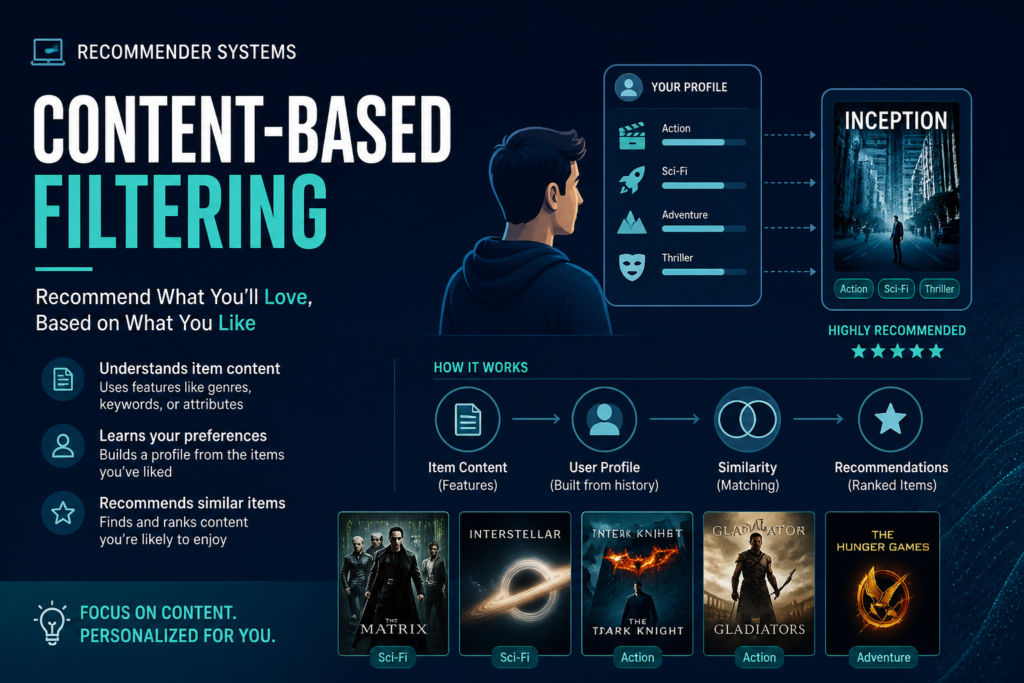
Content based filtering uses item features + user preferences. Idea for Content Based filtering – “Recommend items similar to what the user liked before”.
We have 3 types of data –
users.dat
user_id, gender, age, occupation
Optional features (we’ll use later)
movies.dat
Toy Story → Animation | Comedy Heat → Action | Crime | Thriller These are features
ratings.dat
Tells what users like
Key Idea of Content Based Filtering
A. Represent movies as vectors –
Toy Story → [Animation=1, Comedy=1, Action=0, …]
Heat → [Action=1, Crime=1, Thriller=1]
This becomes:
X (movie feature matrix)
B. Build User Profile
For a user:
liked → Action movies
disliked → Romance
User vector becomes:
[Action=high, Romance=low, …]
C. Predict
score=user_profile . movie_features
SAME dot product idea as before
But now features are explicit, not learned
Step 4: Major Concept Shift
| Collaborative | Content-Based |
|---|---|
| Learns X | Uses X directly |
| Learns Θ | Computes Θ from data |
| Hidden features | Explicit features |
What We Will Build
We will:
Step 1: Convert genres → vectors
Step 2: Build user profile from ratings
Step 3: Compute similarity
Step 4: Recommend movies
I have created the basic simple content-based filtering recommender system for understanding the core concept here –
https://github.com/INNOMIGHT/how-ai-ml-algorithms-work/blob/main/recommender_systems/content_based_filtering_simple.py
We will move forward with the neural networks based content-based-filtering recommender system which is enterprise level and solves major issues faced in collaborative filtering algorithm,
So, Let’s Start!
In the above repository it is simple/classic recommender system using content-based filtering.
Now we will build Advanced/Neural version.
Architecture
Movie Network
movie features → neural network → Vm(i)Output:
Vm(i) = embedding vector for movie i
User Network
user data + history → neural network → Vu(j)Output:
Vu(j) = embedding vector for user jBoth Neural Networks can have different hiddent layers but output layer needs to be the same size.
If you want to learn about Neural Networks – you can read here along with implementation from scratch as well as tensorflow – https://vaibhavshrivastava.com/digit-recognizer-building-neural-network-from-scratch-only-numpy-and-pandas/
Prediction
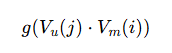
Two cases:
Regression (ratings):
Probability (click/like):
It is something like the network i drew below – it is called neural two tower
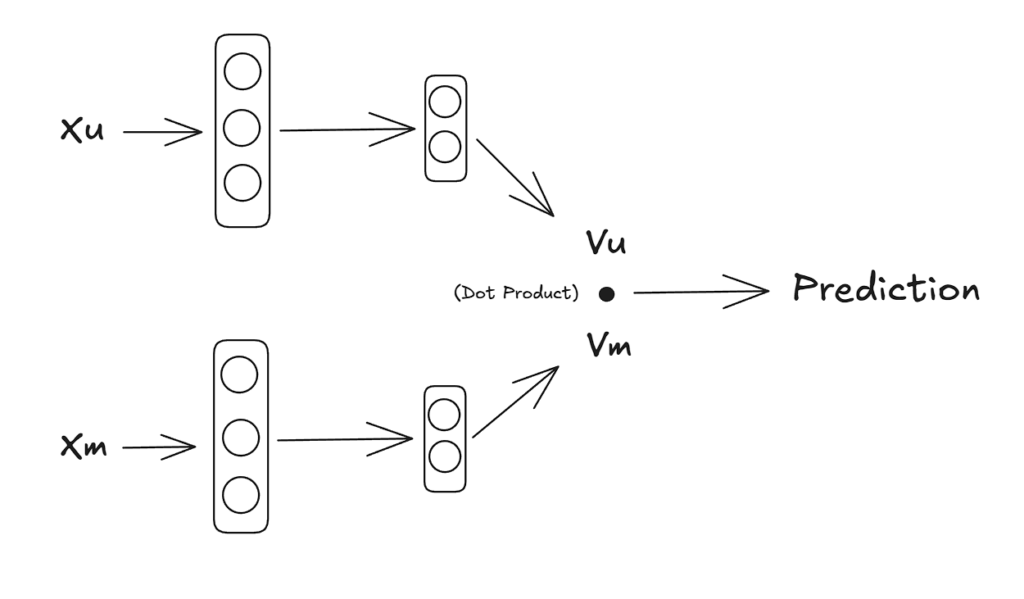
I drew this with https://excalidraw.com/ and other diagrams just so you know and can try.
Cost Function
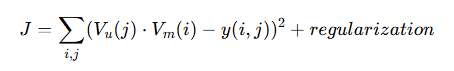
If you have read the collaborative filtering blog, you can relate –
Same structure as collaborative filtering
BUT:
X → replaced by Vm
Θ → replaced by VuWhat’s Actually Different?
Collaborative Filtering
learn X and Θ directlyNeural Content-Based
learn functions that produce embeddingsInstead of learning vectors:
You learn:
Vm(i) = f(movie_features)
Vu(j) = g(user_features)
Generalization
If new movie comes:
just pass features --- get embeddingNo retraining needed
Cold Start Solved
Unlike collaborative filtering:
new user/movie --- still worksSimilar Movies
You must have guessed it, for similar movies we just need the distance between the vectors. If distance is small, similar movies. Distance is large different movie types.
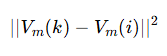
Meaning:
distance between movie embeddings
Interpretation:
- small distance → similar movies
- large distance → different
This is content similarity
This can be precomputed as movie embeddings dont change often.
Why Do We Still Dot Product in Neural Networks?
Even in neural models, we keep:
1. Geometry Interpretation
Dot product =
It captures:
alignment between vectorsMeaning in recommender systems
- If vectors point in same direction → high score
- If opposite → low score
So:
dot product = similarity measureI have explained the cosine similarity in depth in this blog –
https://vaibhavshrivastava.com/designing-a-scalable-face-clustering-pipeline-using-insightface-and-unsupervised-learning/
Other reasons include –
3. Efficient (Production Reason)
Dot product:
- very fast
- scalable
- works with indexing (ANN search)
This is why systems like YouTube/Netflix use it
4. Differentiable
Needed for training:
clean gradients
stable optimization
Neural Content Based Model Implementation –
I strictly recommend reading the comments on the code in notebook or in repository (it will make this much clearer and easier to understand) –
Github Repo – https://github.com/INNOMIGHT/how-ai-ml-algorithms-work/blob/main/recommender_systems/content_based_filtering_neural_networks.py
Kaggle Notebook – https://www.kaggle.com/code/innomight/recommendation-systems-content-based-filtering/
Step 1: Prepare Data
We’ll use:
- movie features → input to movie network
- user history → input to user network
Step 2: Model Architecture – Build Neural Networks
We build: As seen earlier
User Tower: input → dense → embedding (Vu)
Movie Tower: input → dense → embedding (Vm)
"Users who like X features → like movies with similar features"
Here is the Kaggle Notebook for complete implementation - https://www.kaggle.com/code/innomight/recommendation-systems-content-based-simple
STEP 3: Combine Model
model = build_two_tower_model(...)What happens
dot_product = Dot(user_embedding, movie_embedding)This computes:Final model:
(user, movie) -> predicted rating
STEP 4: Compile Model
model.compile(optimizer, loss='mse')Meaning
- optimizer → how weights update
- loss → how error is measured
MSE:
STEP 5: Training
model.fit(...)What happens internally
For each batch:
- forward pass
- compute prediction
- compute loss
- backpropagation
- update weights
This is gradient descent automatically
STEP 6: Inference (Prediction)
model.predict(...)What we are doing
For each movie:
(user, movie) → score
STEP 7: Ranking
top_indices = np.argsort(scores)[::-1][:10]Sort movies by predicted score
Refer to the notebook for complete code and implementation.
If you feel missing or lost at any points, that means you have missed previous information which (dont worry) you can get in these –
Give it a read. Until next time ^^.
Comments