
Scaling your data is a small data pre-processing step but an important one. Before going into the types and which scaler to use according to different purpose and needs. Let us talk about why do we need to scale. Why is it important and beneficial to scale data and later we will see which scaler to use and why.
Importance of Scaling Data
Scaling is a critical preprocessing step in machine learning and data analysis. It involves transforming features in your data so that they are on the same scale. Here’s why scaling is important:
Improves Convergence in Optimization Algorithms
Many machine learning algorithms use optimization techniques (like gradient descent) to minimize an error function. If features are on vastly different scales, the optimization process can become inefficient, leading to slow convergence or getting stuck in local minima.
Ensures Equal Importance of Features
Suppose your data have 2 important features Age and Income, now age will be between 0 – 100 range but income would be 20000 – 1000000 or even a bigger range is possible. Importance of features might be hindered if the values between features differ so much. Scaling ensures that each feature contributes equally to the model, allowing the algorithm to weigh all features fairly.
Improves Performance of Distance-Based Algorithms
Same logic as last point applies in this point too. This will break your distance based algorithms like KNN etc.
Prevents Numerical Instabilities
In algorithms that involve matrix computations, such as linear regression or neural networks, large feature values can cause numerical instability. Scaling helps to prevent issues like overflow or underflow during these computations, leading to more stable and reliable models.
Improves Overall Model Performance and Can Be Compulsive In Many Algorithms
It makes the run algorithms run faster and more accurately. Some algorithms like SVM, PCA, and Neural Networks, inherently assume that the input features are scaled. They would give inaccurate results if you feed them unscaled data.
I can add more points to why scaling data properly is important but I think you get the idea now. So let us get into the types of Scaling algorithms and where should be use them.
Types of Scalers
There can be various algorithms used to scale your data and you can create your own one too but let us see what types are most commonly used –
- Standard Scaler
- Min Max Scaler
- MaxAbs Scaler
- Robust Scaler
- Normalizer
How Most Used Scalers Work
Standard Scaler
If your features have a Gaussian Distribution (data near the mean are more frequent in occurrence than data far from the mean), then standard scaler will do the job.
Working – This simply works around variance (measurement of the spread between numbers in a data set). So it looks how much the data is spread / dispersed using the mean of the data (you must have guessed it).
What it does is it takes the value and it subtracts mean of that data / feature from it and divides by the standard deviation.
Let us understand by example –
Consider the following data: [2, 4, 6, 8, 10]
Mean: 6
Standard Deviation: 2.828
Now, standardize the number 8
z = (8 – 6)/2.828 ≈ 0.707
Here, the standardized value (Z-score) of 8 is approximately 0.707. This indicates that 8 is about 0.707 standard deviations above the mean.
We do this for the data and data is standardized and most values will be around 0 and 1 depending on the dispersion of that point from the mean.
NOTE – Consider reading about statistics and its formulas for mean, standard deviation, variance, median etc. if you do not know well about it. It will help you visualizing data and will benefit you greatly.
Min-Max Scaler
The Min-Max Scaler is a normalization technique that transforms data to fit within a specific range, usually between 0 and 1. It does this by linearly rescaling the features based on the minimum and maximum values in the data.
It works in the following way –
Given a dataset with a feature x, the Min-Max Scaler transforms each value xi using the following formula:

Subtract the minimum value from the original value. Divide the result by the range (difference between the maximum and minimum values). The transformed values will now be scaled between 0 and 1 (or any other specified range if you modify the formula).
Example –
Original Data=[10,20,30,40,50]
Minimum Value is 10 and Maximum is 50.

MaxAbs Scaler
You can already imagine how this works by its name. It is similar to min-max scaler and it is a normalization technique that scales data by dividing each value by the maximum absolute value of that feature. This scaling technique is particularly useful for data that is already centered around zero or for datasets with features that contain both positive and negative values.
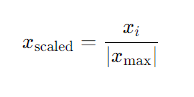
I do not think I need to give an example for this. It is pretty straightforward so let us move to the next one.
Robust Scaler
Now this one has robust in its name because it is less sensitive to data which have outliers in it. Outliers are data points which are far away to other values. It is like that abnormal kid in your school classroom. I recommend checking and removing the outliers from your data but if you cannot transform your data to that extent then why not use something like robust scaler.
The Robust Scaler is a scaling technique that normalizes data by removing the median and scaling according to the interquartile range (IQR), which is the range between the 25th and 75th percentiles.
I myself have only used this once so I won’t talk much about it.
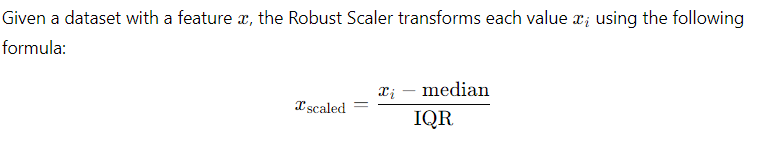
You get the idea why it is not sensitive to outliers as compared to the above scaling methods.
Where To Use Which Scaler
Standard Scaler
- Use When: The data is normally distributed or the algorithm assumes data is centered around zero.
- Ideal For: Linear models, logistic regression, SVM, and neural networks.
- Avoid When: The data contains significant outliers.
Min-Max Scaler
- Use When: You need to scale data to a specific range, usually [0, 1].
- Ideal For: Algorithms that require bounded input, like neural networks and image data.
- Avoid When: The data has many outliers, as they can significantly affect the scaling.
MaxAbs Scaler
- Use When: The data is already centered around zero and you want to scale features to the range [-1, 1].
- Ideal For: Sparse data and datasets with both positive and negative values.
- Avoid When: The data has an uneven distribution or outliers.
Robust Scaler
- Use When: The dataset contains significant outliers or is not normally distributed.
- Ideal For: Scenarios where the data has skewed distributions or heavy tails.
- Avoid When: The data is already well-behaved and free from outliers.
Conclusion
In conclusion, choosing the right scaling technique is crucial for optimizing your machine learning models. Each scaler—whether it’s the Standard Scaler, Min-Max Scaler, MaxAbs Scaler, or Robust Scaler—serves a specific purpose based on the characteristics of your data. Standard Scaler is ideal for normally distributed data, while Min-Max Scaler is perfect for algorithms that require bounded input. MaxAbs Scaler works well with sparse data, and Robust Scaler is your go-to for handling outliers. Understanding when and where to apply each scaler ensures that your data is properly prepared, leading to more accurate and reliable model performance.
NOTE: You can find the scalers implementation and the transformations in this notebook.
Until next time ^^
Comments
[…] Previous Blogs – Regression Model – https://vaibhavshrivastava.com/how-linear-regression-model-actually-works/Feature Engineering – https://vaibhavshrivastava.com/the-importance-of-feature-engineering-in-machine-learning/Logistic Regression – https://vaibhavshrivastava.com/logistic-regression-from-basics-to-code/Scaling Algorithms – https://vaibhavshrivastava.com/scaling-features-how-scaler-works-and-choosing-the-right-scaler/ […]