
This article will be around how to diagnose a machine learning model and fix problems with it. This will also help with choosing the right regularization term, model selection and validation. Designing and training the model is cool but fixing it and making it accurate is important and that is where diagnostics come in. We will see all types of graphs involving high bias or variance and what happens with each dataset (train, test, cross-validation) if one or the other thing or everything is wrong with the model. So lets get to it.
Evaluating a Model
The basic outline of evaluating a model is somewhat like –
- Divide training data into training and test set.
- Fit parameters in minimizing cost function.
- Compute test errors without regularization term.
- Compute training error.
- Keep fixing the error when you reach the threshold.
Now, each of the above point has several things that need to be performed in between and now we will look at those things.
Model Selection
Simplest way for model or neural network architecture selection is –
Split your data into 3 divisions
– Mtrain –> Training Data –> 60 percent
– Mcv –> Cross Validation Set –> 20 percent
– Mtest –> Test Set –> 20 percent
The model selection process involves:
- Finally, use Jtest (test error) to estimate the model’s generalization performance on unseen data.
- Calculate the cost function Jcv (cross-validation error) for each candidate model (for example, for different degrees of a polynomial).
- Choose the model that gives the lowest Jcv to prevent overfitting or underfitting. The parameters are selected based on the performance on the cross-validation set.
Diagnosing Bias and Variance
Let us first see what problems might occur if we do not diagnose and correct the problems.
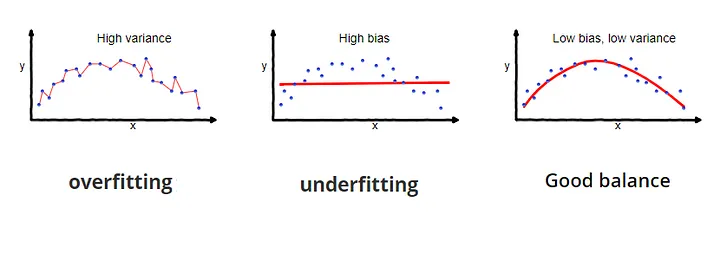
Let us study the graphs shown above one by one –
1. Overfitting graph – Overfitting occurs due to High Variance (one of the reasons). Higher degree used than required. Eg: w1x + w2x2 + w3x3. (HIGH VARIANCE)
2. Underfitting graph – Underfitting occurs due to High Bias (one of the reasons). Lower degree used than required. Eg: wx + b
3. Good Balance – Just right degree used to cover the data points as closely as possible that will help in generalization the most. Eg: w1x + w2x2 + b
Points and Tips that can help in diagnosis –
- In High Bias –> Underfit
Jtrain is high
Jcv is high - In High Variance –> Overfit
Jtrain is low
Jcv is high - Just Right –> Good Generalization
Jtrain is low
Jcv is low
Let us look at this graph –
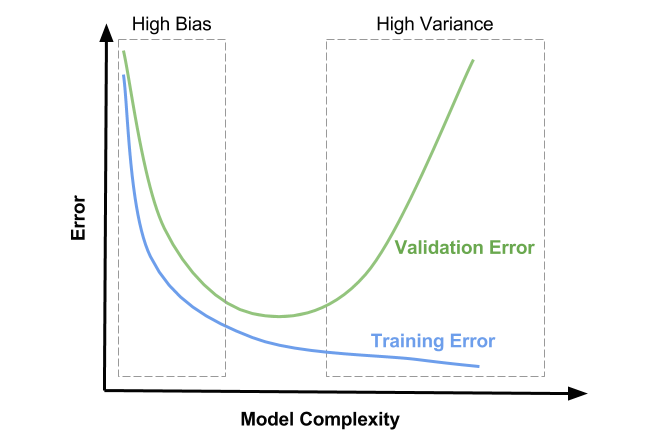
As the degree of the polynomial increases, the behavior of Jtrain and Jcv can be explained in terms of bias and variance:
1. Training Error (Jtrain):
- When you increase the degree of the polynomial, the model becomes more flexible, allowing it to fit the training data more closely.
- With a higher-degree polynomial, the model can capture more complex patterns in the training data, leading to a reduction in the training error (Jtrain). In fact, if the degree is high enough, the model can “memorize” the training data, driving the training error to near zero (overfitting).This is why Jtrain decreases monotonically as the degree of the polynomial increases.
2. Cross-Validation Error (Jcv):
- The cross-validation error behaves differently because it measures the model’s performance on unseen data.
- For low-degree polynomials, the model may not be complex enough to capture the underlying data patterns (underfitting), leading to both high training and cross-validation errors.
- As the polynomial degree increases, the model improves and captures more complex relationships, reducing both Jtrain and Jcv.
- However, when the polynomial degree becomes too high, the model starts to overfit the training data. It fits the noise and specific details of the training set rather than generalizing well to new data. This increases the cross-validation error (Jcv).This is why Jcv follows a parabolic shape: it first decreases (as the model improves) and then increases (as the model overfits).
NOTE: Read the above points carefully.
Bias and Variance with Regularization
Choosing the right regularization terms becomes simpler if we apply the diagnostics correctly.
If you chose –
– Large Lambda λ –> High Bias (Underfit)
– Small Lambda λ –> High Variance (Overfit)
– Intermediate –> Just Right
How to chose λ
- Try λ = 0
- Keep Doubling λ (I don’t want no smartass saying double of zero is zero) (1, 2, 4, 8)
- Using Cross Validation Set, chose best value for λ
- Pick λ with lowest error (using CV)
TASK FOR YOU – Figure out why large λ results in High Bias and small λ results in High Variance.
HINT – It is multiplied with you know what, making you know what small or big 😛
Establishing Baseline Level of Performance
Imagine a speech recognition model –
We get a Jtrain = 10.8% and Jcv = 14.8 %
Consider Human Level Error = 10.6% (because of noise etc)
Baseline Performance = 10.6%
Training Error = 10.8%
Cross Validation Error = 14.8%
Gap between the three must be as low as possible. What if the gap is larger? Lets look at that –
Gap Between Baseline and Training Error High = High Bias
Gap Between Training Error and Cross Validation Error = High Variance
Gap Between All Three High = Both
The Solution comes next –
Debugging: What To Try Next
This will be small but effective portion (like a cheatsheet).
- Get More Training Examples
- Try Smaller Set of Features
- Try Getting Additional Features
- Try Adding Polynomial Features
- Decrease λ
- Increase λ
1, 2, and 6 are for High Variance Fix
3, 4, and 5 are for High Bias Fix
You can also call the above cheatsheet for variance and bias fix.
Iterative Loop of ML Dev
Choose Architecture (model, data, etc) —> Train Model —> Diagnostics
Conclusion
In summary, effective machine learning diagnostics involves carefully analyzing the behavior of training, cross-validation, and test errors to identify issues like underfitting or overfitting. Using tools such as learning curves and error functions helps fine-tune models and improve their generalization. By monitoring these diagnostics, you can select the best model and ensure it performs well on unseen data.
This is an undervalued step but it is the most important one.
Until Next Time ^^
Comments